and parallel oriented functions.
7) DataStage server executed by dataStage server environment but parallel executed under control of dataStage runtime environment
8) DataStage compiled in to BASIC(interpreted pseudo code) and Parallel compiled to OSH(Orchestrate Scripting Language).
9) Debugging and Testing Stages are available only in the Parallel Extender.
10) More Processing Stages are not included in Server example, Join, CDC, Lookup etc…..
11) In File Stages, Hash file available only in Server and Complex falat file , dataset , lookup file set avail in parallel only.
12) Server Transformer supports basic transforms only, but in parallel both basic and parallel transforms.
13) Server transformer is basic language compatability, pararllel transformer is c++ language compatabillity
14) Look up of sequntial file is possible in parallel Jobs
15) . In parallel we can specify more file paths to fetch data from using file pattern similar to Folder Stage in Server, while in server we can specify one file name in one O/P link.
16). We can simulteneously give input as well as output link to a seq. file Stage in Server. But an output link in parallel means a reject link, that is a link that collects records that fail to load into the sequential file for some reasons.
17). The difference is file size Restriction. Sequential file size in server is : 2GB; Sequential file size in parallel is : No Limitation.
18). Parallel sequential file has filter options too. Where you can specify the file pattern.
除此之外,还有很多细节是相差很大的,做时需要注意。使用时很简单的感觉,Server Job可以很容易的上手,开发也很快,性能就差一些(就像MySQL);Parallel Job要求很严格,掌握起来有点难,但性能很强劲(就像DB2)。
4.4 JOB和Stage
Server Job和Paralel Job都是利用各种不同功能的Stage的组合,实现具体的E T L功能,而Job Sequence则是将Server Job或者Parallel Job或者Job Sequence连接起来,实现Job间的依赖等。JOB中用到的参数,在DS Administrator中定义的,可以直接引用,在参数文件或者参数表中定义的,就得用程序调用赋给相应的JOB了。
数据仓库中用到的事实表,维表,缓慢变化维,增量,全量等等概念,在DS中没有直接对应的Stage,和用SQL一样,需要我们编程实现相应的逻辑。
下面两个示例,实现的功能都是一样的,都是从文本文件中读取数据,进行简单的字段类型转换后,入库。只不过是Parallel Job是入DB2,Server Job是入Oracle。
4.4.1 Parallel Job和Stage
一般我们创建一个Job,大概都是如下的样子。和写程序实现一样,我们需要知道源和目标是什么,中间做什么处理,然后实现之。用DS也是一样,只是将不同的Stage组合起来,实现相应的功能。Job和Stage中还有很多其他的东西,只是用了最经常用的功能和Stage进行示例。
这个Job就是先将同一周期的数据删掉,然后从Sequential File Stage中按照定义的接口规范读取数据,在Transformer Stage中对字段进行转换,最后在DB2 Stage中将其入库。

其他复杂的Job也大概是这样,也都是按照实现的功能,将不同的Stage组合起来。
Job中用到的参数都是在Job Properties中定义的,另外一些通用的功能(执行前对一些文件的处理)也是在这里实现的


Parallel Job和Server Job这方面基本上是一样的。接下来,就按照顺序一个一个Stage大概说一下。先看一下Sequential File Stage


配置好文件路径和其他参数后,就View Data一下,好多错误都是因为配置不对引起的。文本文件的操作,都是用Sequential File Stage。对于中间用到的文件,可以用Data Set Stage,这个是DS内部实现的,性能很好。
读到数据后,就用Transformer执行类型转换、源和目标的字段映射等。ETL中用到的源和目标字段的对应关系,都是通过Active Stage以”拉线”的方式实现的。没有办法在参数表中定义好,在此引用。倒是可以用文档记录不同的源和目标之间的映射关系。整个E T L,也都是用Passive 读到数据后,用不同的Active Stage组合,实现关联、去重、转换等。
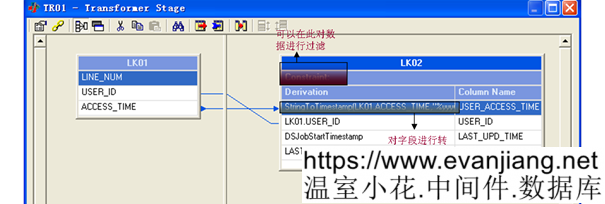
其中字段LAST_UPD_TIME和CYCLE_TIME是我们在ETL中用到的,LAST_UPD_TIME表示这批数据的实际入库时间,CYCLE_TIME表示这一批数据的数据时间,当然根据项目需要,可以添加其他的字段来标示。对于增量的Job,每次执行前都是先将同一CYCLE_TIME的数据删掉,然后入库,这样做就是为了支持重做。对于全量JOB,都是将表中的数据Truncate掉,然后入库。
处理完后,就可以入库了
以下文章点击率最高
Loading…